The Browser's Other Scripting Language
You’d think that with all the excitement about AJAX and other new client-side (that is, browser-side) architectural focus that there would be a bit more lovin’ for the other browser-side scripting language besides JavaScript. But despite being turing-complete XSLT isn’t as widely talked about as its more glamourous sibling.
Herewith some observations on the current sorry state of XSLT in the browser, which may point to the reasons for its neglect.
Tree, Transform Thyself
XSLT is a language for transforming trees of input XML nodes into output trees. It is designed to allow templates to be constructed which are matched against patterns in the input tree. When a match occurs, the template is used to construct the relevant output tree. There’s more to it than that, but at its heart XSLT is all about transformation of XML trees.
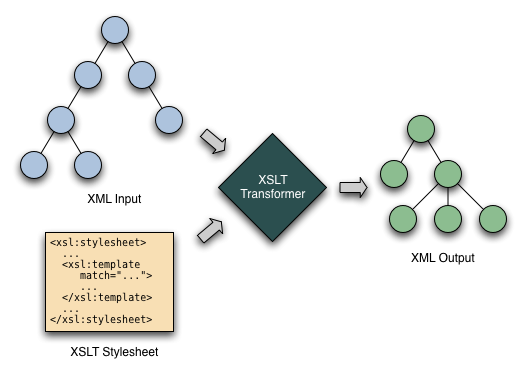
When you first attempt to use XSLT it can be quite intimidating. The syntax itself is all XML and that introduces some complexity of its own, although it provides a perfectly natural way of specifying output tree templates. It takes some time to get your head around the fact that you’re not specifying how the transform happens. Instead you get the best out of XSLT by specifying the mapping of outputs to inputs. XSLT has a lot in common with functional programming in this respect and others.
When it works well, XSLT is almost elegant (if I do say so myself). When it doesn’t it can be downright byzantine, but let’s not get ahead of ourselves.
Nonetheless I think the basic idea is pretty powerful. It also happens to fit in really nicely with the REST architectural style (at least as I understand it) and so is very web-friendly. Browser accesses the raw XML of a resource and locally transforms it to an HTML representation. It is even backwards compatible with Web 1.0.
When Good Transforms Go Bad
Sometimes XSLT can be very frustrating. Sooner or later you run into one of the many gotchas. For example, there is no way to group a given set of XML nodes (eg to find the unique nodes) and this requires a hack to work around.
Another hack which is sometimes required is the use of the node-set extension function (or equivalent, sometimes known as nodeset). This is a bit technical but it basically allows the use of intermediate results.
In XSLT 1.0 there is a thing called a Result Tree Fragment. This can be assigned to a variable and manipulated in certain ways but it cannot be treated as anything other than a piece of (potential) output. In other words, you can’t re-process it using templates or even explicit iteration. As the name implies, the node-set extension function is used to convert the RTF back into a regular node set which can be used as an intermediate result.
This is an incredibly useful function that probably should have been part of the original XSLT 1.0 language specification. In XSLT 2.0 they acknowledged the usefulness of intermediate results by removing RTFs altogether, and allowing allowing node sets to be created directly within variable declarations.
As you might have guessed, the problem with the node-set extension function is that, well, it’s an extension of the language. And thus subject to the whims of implementers.
Best Viewed in Internet Explorer
OK I’ll come out and say it. Most of the major browsers support XSLT, but Internet Explorer is the only one that provides the node-set function.
Firefox? They use the Transformiix XSLT engine which doesn’t provide the function. They’ve been thinking about it since 2003 and despite having a patch they’re still thinking. [Update 31-Jan-2007: Looks like they’ve stopped thinking and started committing. Firefox 3.0 is the target. ]
Safari? Same story, although their XSLT engine is libxslt which does support node-set through the EXSLT standard extension library, but the WebKit guys haven’t found time to enable it yet.
Opera? No XSLT at all. [Update: OK Opera 9 has “near complete XSLT”. Whether this includes node-set or not, I have no idea. Further Update: Yep, it does ]
I’ve bagged Internet Explorer in the past, but on this particular (and admittedly fairly esoteric) feature, IE has it all over the competition.
Working Draft’s Paradise
Of course it wouldn’t be a Microsoft product if there weren’t some frustrating limitations. Read the full details yourself, but as I understand it, the situation is as follows.
Microsoft’s XML toolkit is called MSXML and in previous releases they implemented an earlier draft of XSLT which is known as WD-xsl (WD for Working Draft). And it really was a draft because the early language bears very little resemblance to XSLT 1.0.
Being conscientious engineers that they are, Microsoft allowed MSXML installations to support both the old WD-xsl and the new XSLT 1.0 stylesheets. So far so good, but unfortunately they did not engineer it to automatically determine which type of stylesheet it was being asked to process. And to maintain compatibility with existing code, the WD-xsl language was chosen as the default.
Maybe I should go looking for security vulnerabilities in WD-xsl, which if found might cause Microsoft to remove WD-xsl altogether?
As a result, Internet Explorer cannot process the standard <?xml-stylesheet href="foo.xsl"?> processing instruction. IE doesn’t know whether the foo.xsl referred to in this instruction is WD-xsl or XSLT 1.0, and it defaults to the former. In other words they broke an implementation of a standard in favour of an implementation of a draft standard. (Does all this sound familiar?)
“To Help Protect Your Security…”
So besides the standard XML Processing Instruction the next best way to invoke an XSLT 1.0 stylesheet in Internet Explorer is to do so from JavaScript. You do something like:
function init() { // load XML source document var source = new ActiveXObject("Msxml2.DOMDocument.4.0"); source.async = false; source.load("source.xml"); // load XSLT stylesheet document var stylesheet = new ActiveXObject("Msxml2.DOMDocument.4.0"); stylesheet.async = false; stylesheet.load("stylesheet.xsl"); // transform the source using the XSLT stylesheet target.innerHTML = source.transformNode(stylesheet); }
(Code stolen from perfectxml.com article linked above)
Note the use of ActiveXObject. If you try to run this code, IE dutifully warns you about the potential hazards of ActiveX and the need to “protect your security” in a yellow information bar. This is obviously death for websites that want to use XSLT. Bafflingly, it gives you this warning even when you run it locally from your disk.
Of course XSLT scripts are locally-executed and hence potential security hazards, so I don’t want to trivialise the decisions that Microsoft has made here. But really it shouldn’t be too hard to secure an XSLT implementation. Besides, JavaScript is far worse — both in terms of potential for, and history of, security vulnerabilities — and that isn’t blocked.
Whither Browser-based XSLT?
So the reasons why we don’t see more XSLT usage in the browser should be obvious. The outlook for the future doesn’t look too great either.
IMHO the best solution is to charge on with XSLT 2.0. Microsoft have stopped developing MSXML but their .NET replacement is still under development. Speculation is rife that they may be including XSLT 2.0 support. [Update: confirmed] Also there is the Saxon XSLT engine, and early rumblings from the Apache Xalan crowd and Oracle. Although none of these are likely to be used in the browser, they may provide some impetus for XSLT 2.0 as a whole..
Come on Firefox guys, come on WebKit guys, come on Opera guys. XSLT 2.0 looks powerful and useful. Don’t let Microsoft beat you to the punch - again.
2 Comments